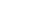




发布时间:2024-04-22 14:00:36 浏览:
主页 | https://optuna.org/
Optuna是一个用于超参数优化的Python库,可以帮助我们自动化地选择最优的超参数组合,从而提高机器学习模型的性能。Optuna使用贝叶斯优化算法来搜索超参数空间,可以支持大部分机器学习框架,如TensorFlow、PyTorch、scikit-learn等。Optuna是一个非常易于使用的Python库,具有以下功能:
- 轻量级、多功能和跨平台架构:Optuna的依赖较少,安装简单,可以在不同的平台上运行,并且可以处理各种不同的任务。
- Python式的搜索空间:Optuna使用熟悉的Python语法,如条件语句和循环,来定义搜索空间。这使得用户可以更方便地定义超参数的搜索范围,并且更容易理解和调整搜索空间。
- 高效的优化算法:Optuna采用最先进的超参数采样算法和最有效的对无望trial进行剪枝的算法,能够更快地找到最优解,并且避免了浪费资源在无效的试验上。
- 易用的并行优化:Optuna可以很容易地扩展到多个worker上进行并行优化,帮助用户更快地完成超参数搜索,并且可以根据需要增加或减少worker数量。
- 便捷的可视化:Optuna提供了可视化工具,如查询优化记录、绘制学习曲线等,可以帮助用户更好地理解试验结果和选择最优的超参数组合。
Optuna 可以通过 pip 进行安装,要求Python版本大于等3.7 或更新版本。
# 安装optuna
pip install optuna
# 安装optuna可视化仪表板
pip install optuna-dashboardOptuna的核心是Trial对象,代表了一次超参数组合的试验。Optuna根据已有的试验结果,自动选择下一组超参数组合进行试验,并逐渐收敛于最优解。使用Optuna进行超参数优化的基本步骤如下:
- 定义搜索空间:定义超参数的搜索空间,可以使用Optuna提供的分布函数来定义超参数的取值范围。
- 定义目标函数:目标函数是需要优化的模型,可以是任何可调用对象,如Python函数、类方法等。目标函数的输入是超参数的值,输出是模型的性能指标。
- 创建Optuna试验:创建Optuna试验对象,并指定目标函数和搜索算法。
- 运行Optuna试验:运行Optuna试验,进行超参数搜索。在每次试验结束后,Optuna会更新超参数的取值,并记录当前试验的性能指标。可以设置尝试的次数或时间,来控制搜索空间的大小和搜索时间的限制。
- 分析试验结果:在试验结束后,可以使用Optuna提供的可视化工具来分析试验结果,并选择最优的超参数组合。
下面示例展示了使用Optuna优化一个预定义的目标函数的示例:
import optuna
# 定义objective要优化的函数,最小化目标函数(x - 2)^2
def objective(trial):
# 定义超参数的搜索空间,x的空间是-10到10之间的浮点数
x=trial.suggest_float('x', -10, 10)
return (x - 2) ** 2
# 创建一个study对象并调用该optimize方法超过 100 次试验
study=optuna.create_study()
study.optimize(objective, n_trials=100)
# 输出搜索出的最佳参数
print(study.best_params)
下面是一个示例代码,用于在scikit-learn的SVM模型中使用Optuna进行超参数优化:
import optuna
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
# 加载鸢尾花数据集
iris=datasets.load_iris()
X_train, X_test, y_train, y_test=train_test_split(iris.data, iris.target, test_size=0.2)
# 定义目标函数
def objective(trial):
# 定义搜索空间
C=trial.suggest_loguniform('C', 1e-5, 1e5)
gamma=trial.suggest_loguniform('gamma', 1e-5, 1e5)
# 训练SVM模型
clf=SVC(C=C, gamma=gamma)
clf.fit(X_train, y_train)
# 评估模型性能
score=clf.score(X_test, y_test)
return score
# 创建Optuna study
study=optuna.create_study(direction='maximize')
# 运行Optuna搜索
study.optimize(objective, n_trials=100)
# 打印最佳超参数和得分
print('Best hyperparameters: ', study.best_params)
print('Best score: ', study.best_value)
还可以使用Optuna优化pytorch模型的超参数,例如层数和每层中的隐藏节点数:
import torch
import optuna
# 1. 定义目标函数,用于最大化
def objective(trial):
# 2. 使用trial对象建议超参数取值
n_layers=trial.suggest_int('n_layers', 1, 3)
layers=[]
in_features=28 * 28
for i in range(n_layers):
out_features=trial.suggest_int(f'n_units_l{i}', 4, 128)
layers.append(torch.nn.Linear(in_features, out_features))
layers.append(torch.nn.ReLU())
in_features=out_features
layers.append(torch.nn.Linear(in_features, 10))
layers.append(torch.nn.LogSoftmax(dim=1))
model=torch.nn.Sequential(*layers).to(torch.device('cpu'))
# 3. 训练模型并计算准确率
optimizer=torch.optim.Adam(model.parameters(), lr=0.01)
criterion=torch.nn.CrossEntropyLoss()
for epoch in range(10):
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
output=model(data)
loss=criterion(output, target)
loss.backward()
optimizer.step()
accuracy=test(model, test_loader)
return accuracy
# 4. 创建Optuna study对象并运行超参数搜索
study=optuna.create_study(direction='maximize')
study.optimize(objective, n_trials=100)
Optuna Dashboard为 Optuna 提供了实时 Web 仪表板功能。通过Optuna Dashboard可以查看优化历史记录、超参数重要性等。
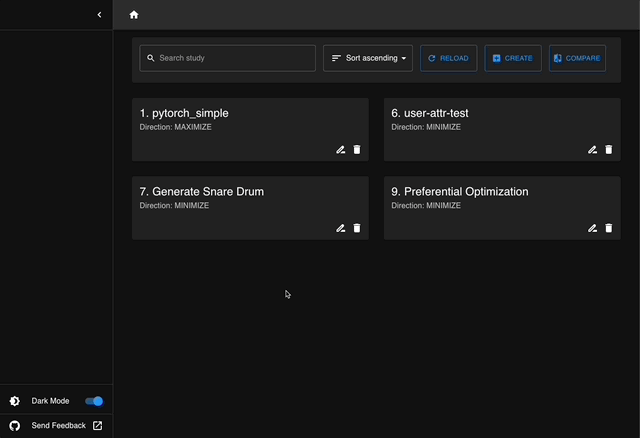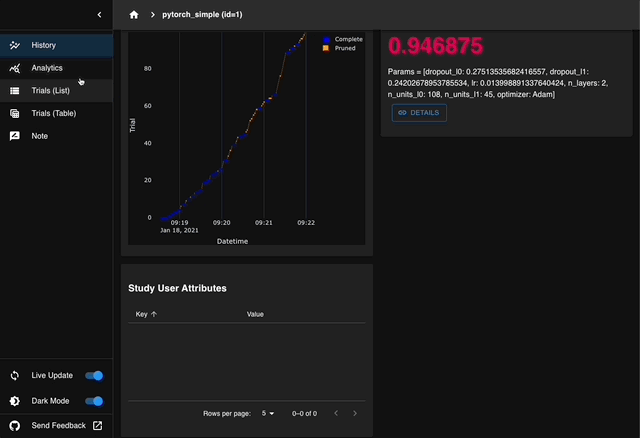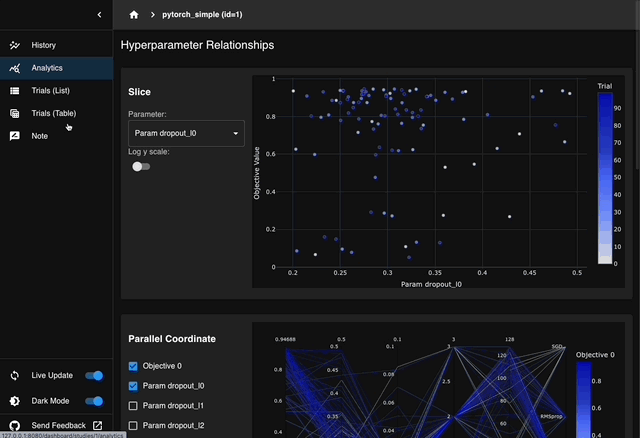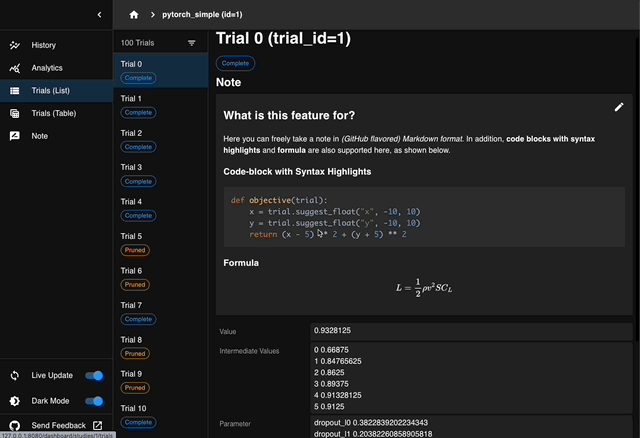
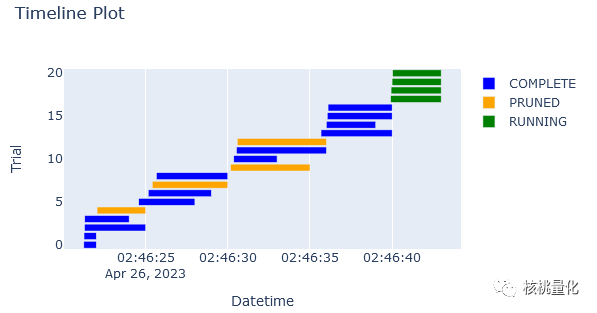
Optuna还支持以时间线图的方式可视化了每个试验的进度(状态、开始时间和结束时间)。在此图中,水平轴表示时间,试验沿垂直方向绘制。每个试验表示为一个水平条,从试验开始到结束绘制。通过此图,您可以快速了解优化实验的整体进展情况,例如并行优化是否正在适当进行,或是否有试验花费异常长的时间。
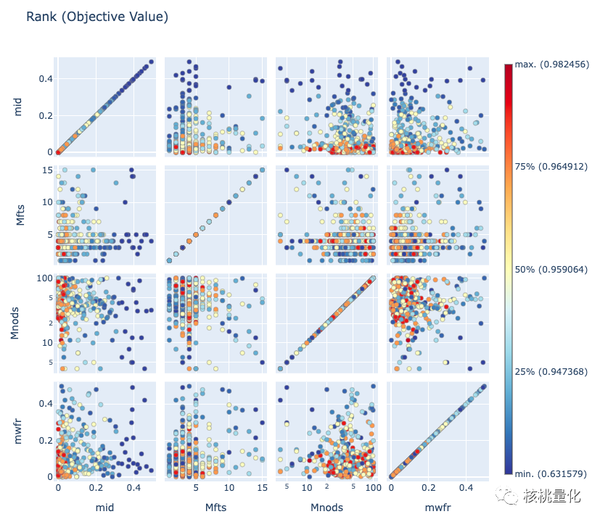
Optuna还支持使用plot_rank函数来可视化参数和目标值之间的关系。如下图,垂直和水平轴表示参数值,每个点表示单个试验,可以根据点的颜色来确定排名。plot_rank可视化针对异常值具有鲁棒性,因为它忽略目标值本身,并专注于参数之间的排名。